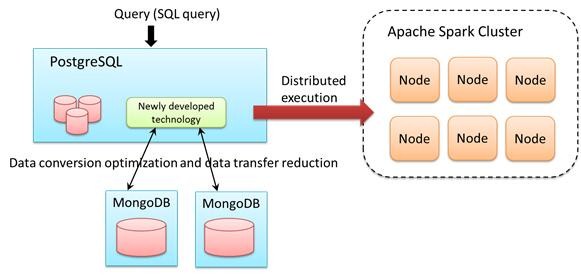
Fujitsu Laboratories Ltd. is working on a new technology that would help in the integration and rapid analyis of NoSQL databases. This is used for accumulating large volumes of unstructured IoT data with relational databases for analysing data for mission-critical enterprise systems. The newly developed technology would optimise data conversion and reduce the amount of data transfer by analysing SQL queries so as to seamlessly access relational databases and NoSQL databases.
This technology could be put to use in numerous important applications. For instance, a retail store could continually roll out a variety of IoT devices so as to collect information like customers’ in-store movements and actions. This would allow them to relate this information to the existing mission-critical systems, thus contributing to the implementation of one-to-one marketing strategies.
Development Background
IoT and sensor technology are improving day-by-day allowing the collection of new information that was earlier difficult to obtain. It is expected that connecting this new data with the existing mission-critical informations systems would pave the way for analyses on a number of fronts that were earlier not possible. For example, the retail stores can now obtain a lot of IoT data like where the customers are lingering in the store or which products the customers looked at and picked up frequently, etc. by analysing image data from the surveillance cameras.
Issues
A predefined data format is important to convert the unstructured data into structured data but with the growing use of IoT, It has become difficult to define formats in advance as new information is being added. At the same time, analysts have been searching for methods that don’t need pre-defined data formats. However, if a format can’t be defined in advance then the conversion processing overhead is very important and this creates an issue with longer processing times while undertaking an analysis.
Details of the Technology
This technology analyses SQL queries that include access to data in NoSQL database in order to extract the portions specifying necessary fields and their data type and identify the required data format. Later, on the basis the obtained results, the query is optimised and overhead is reduced through bulk conversion of the NoSQL data, rendering performance equivalent to the existing processing with a pre defined data format.
The technology migrates some of the processing like filtering from PostgreSQL side to the NoSQL side by analysing the database query. It minimises the data transferred from the NoSQL data source and accelerates the process.
It automatically determines the optimal data partitioning thereby avoiding unbalanced load across the Apache Spark nodes.
Filed Under: News

Questions related to this article?
👉Ask and discuss on Electro-Tech-Online.com and EDAboard.com forums.
Tell Us What You Think!!
You must be logged in to post a comment.