Machine learning is the future of computer theory and computational electronics. In the past decade, advances in machine learning, deep learning, and artificial intelligence have changed how computing power is utilized. In the future, the developers may not be writing specific user-defined programs. Instead, they will be fabricating algorithms to let the computers perform assigned tasks independently. Computers, microcontrollers, and specialized processors will not be running predefined software/firmware routines. Instead, they will be live machines observing, learning, and autonomously putting through valuable tasks.
Machine learning and artificial intelligence aim to make computers and microcontrollers autonomous machines empowered with human-like cognitive abilities. Machine learning as narrow artificial intelligence is now frequently used on all platforms and applications, including web servers, desktop applications, mobile applications, and embedded systems.
We have already discussed that to start with machine learning, one needs to select a programming language. We have also discussed that each programming language is also dominant in one or the other business domain. However, programming language selection remains immaterial as the concepts of machine learning problems and algorithms remain fundamental irrespective of the selected programming language or language-specific tools, packages, or frameworks. Python is the most friendly programming language for beginners to kick start with machine learning and deep learning solutions. Python is syntactically simple and has time-tested tools and frameworks to solve any machine learning problem. Pythonic machine learning can even be applied in simple devices running over microcomputers and microcontrollers.
The next step is learning to use tools, libraries, and frameworks of a chosen programming language for machine learning. Often these tools and packages are related to preparing datasets, acquiring datasets (from sensor data, online data streams, CSV files, or databases), cleaning data (called data wrangling), generalizing and normalizing datasets, data visualization, and finally applying learning data to a machine learning model, which may be following one or several machine learning algorithms.
In this article, we will discuss classifying various machine learning algorithms which can make it easier to select a particular algorithm or deduce a list of applicable algorithms for a given problem. The classification of ML algorithms is not fundamental in any way. It is an arbitrary classification that often changes as new algorithms are invented and further advances in machine learning techniques are made. Still, the classification helps in a broad understanding of various algorithms and presents a clearer view of their applicability to different machine learning problems.
Broad classification
The broadest classification of machine learning algorithms is done based on machine learning techniques. This also serves as the fundamental classification of algorithms as almost all varieties of algorithms essentially fall in one of the following four machine learning techniques.
- Supervised learning
- Unsupervised learning
- Semi-supervised learning
- Reinforcement learning
Supervised learning algorithms
In supervised learning, the machine is expected to deliver known outcomes. The training data is already supplied with predefined labels or outcomes. The algorithm has to identify matching characteristics or common features among training data that reference predefined labels/outcomes. Post-training, the same features/attributes are compared to label unknown data.
For example, a microcomputer may be supplied with a sensor dataset of temperature, light, and humidity. Then, it may be modeled to predict day or night or estimate the time of the day. In such a case, in contrast to a typical embedded program routine, a machine learning model has better chances to come up with malfunctioning of sensors and sensor variations as the machine could autonomously deal with erroneous input data through a rigorous process of supervised learning. A model is considered to be deployable after a thorough process of test and validation
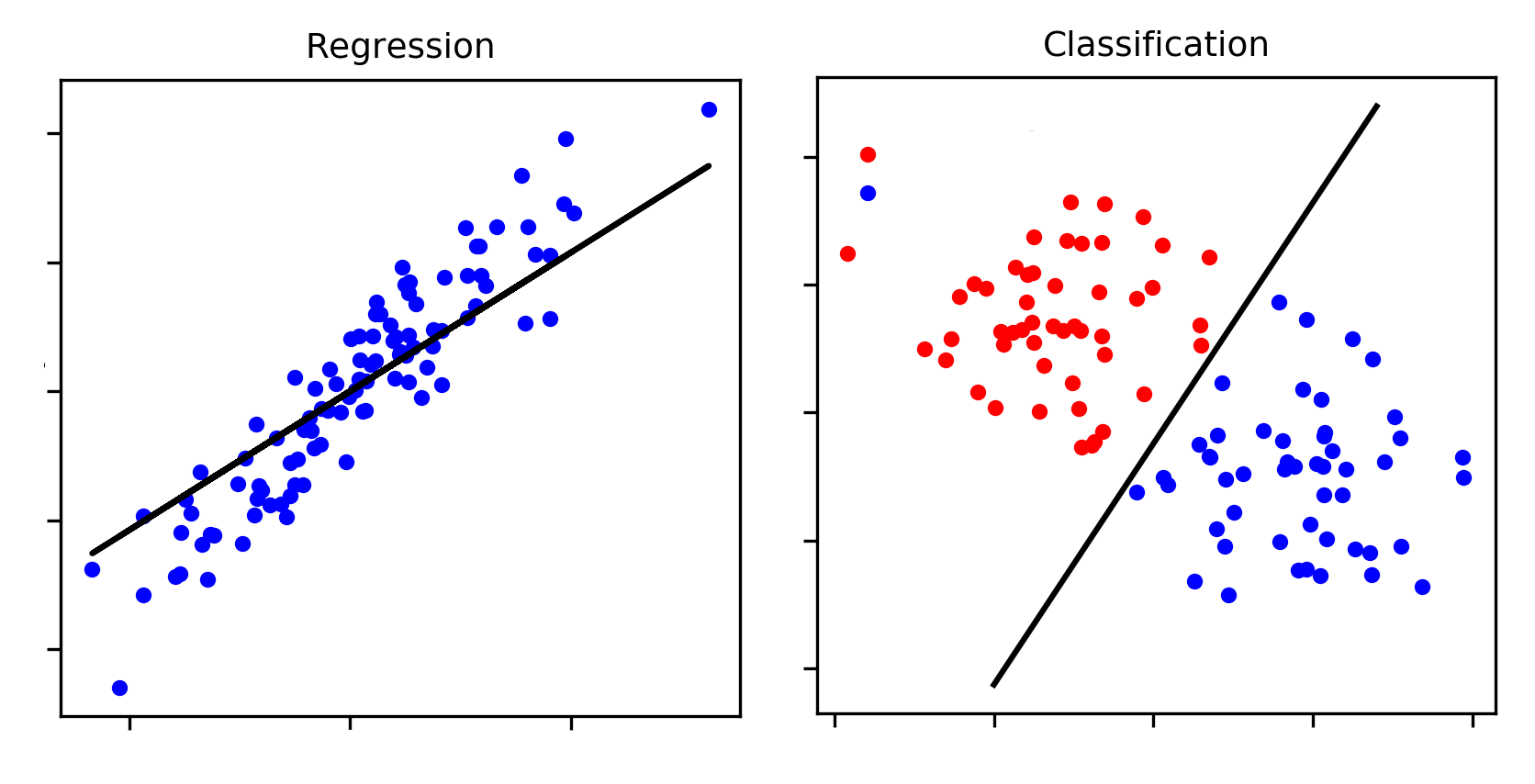
The two most common learning problems are usually solved by supervised learning are classification and regression. Classification deals with labeling input data with predefined labels. Regression deals with deriving outcomes of unknown input data based on learned correlations between training data and known outcomes. The derived outcome is a numerical value or result.
Some of the common machine learning algorithms that fall under supervised learning include K Nearest Neighbor, Random Forest, Logistic Regression, Decision Trees, and Back Propagation Neural Network.
Unsupervised learning algorithms
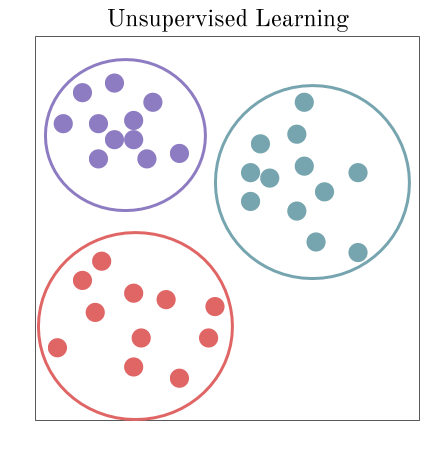
In unsupervised learning, the machine is expected to deliver unknown outcomes. The machine is exposed to unlabelled raw data samples and it must deduce structures present in the input data. This is usually done mathematically by either extracting similarities or removing redundancies. The outcome of machine learning is not a class/label or a numerical output; instead, the output is delivered by grouping similar data samples or identifying the odd ones.
Some of the common problems solved through unsupervised learning are clustering, association rule mining, and dimensionality reduction. Some of the common machine learning algorithms that fall under unsupervised learning include K-Means Clustering, Apriori Algorithm, KNN, Hierarchal Clustering, Singular Value Decomposition, Anomaly Detection, Principal Component Analysis, Neural Networks, and Independent Component Analysis.
Semi-supervised learning algorithms
In semi-supervised learning, the machine is trained with labeled datasets then exposed to unknown data samples for deriving common features/associations among data belonging to the same classes. Alternatively, the machine is first trained on unlabelled data to derive its own classes and then the training is refined by providing labeled datasets. In both cases, the machine has to predict expected outcomes (class or a numerical value) as well as deduce inherent patterns within input data. Semi-supervised learning also deals with the same problems that supervised learning does (i.e. classification and regression) albeit, semi-supervised learning is expected to be finer in its outcomes.
Some of the common machine learning algorithms that fall under semi-supervised learning include Continuity Assumption, Generative Models, Laplacian Regularization, Cluster Assumption, Heuristic Approaches, Low-Density Separation, Discrete Regularization, Label Propagation, and Quadratic Criterion, and Manifold Assumption.
Reinforcement learning algorithms
In reinforcement learning, a system called an agent is developed to interact in a specific environment so that its performance for executing certain tasks improves from the interactions. The agent starts from a predefined initial set of policies, rules, or strategies and then is exposed to a specific environment in order to observe the environment and its current state. Based on its perception of the environment, it selects an optimal policy/strategy and performs actions. In response to every action, the agent gets feedback from the environment in the form of a reward or penalty. It uses the penalty/reward to update its policy/strategy and again interacts with the environment to repeat actions.
Some of the common machine learning algorithms that fall under reinforcement learning include Q-Learning (State-Action-Reward-State), SARSA (State-Action-Reward-State-Action), Lambda Q-Learning, Lambda SARSA, Deep Q Network, NAF (Normalized Advantage Functions), DDPG (Deep Determinant Policy Gradient), TD3 (Twin Delayed Deep Deterministic Policy Gradient), PPO (Proximal Policy Optimization), A3C (Asynchronous Advantage Actor-Critic Algorithm), SAC (Soft Actor Critic), and TRPO (Trust Religion Policy Optimization).

Narrow classification
The classification of ML algorithms based on learning techniques can be short-listed based on their functions or similarities, giving a list of possible algorithms that can be used for a particular learning problem. The rest of the selection of a specific algorithm for a particular problem depends upon the intrinsic details and workings of the shortlisted algorithms and the developer’s own discretion regarding which algorithm will be best suited for a given problem. Machine learning algorithms can be shortlisted as follows on the basis of functions or similarities.
Bayesian Algorithms
These are the algorithms that specifically apply Bayes’ Theorem for solving the supervised learning problems (i.e. classification or regression). Some of the algorithms that fall in this category include Naive Bayes, Averaged One-Dependence Estimators (AODE), Gaussian Naive Bayes, Multinomial Naive Bayes, Bayesian Network (BN), and Bayesian Belief Network (BNN).
Regression Algorithms
Regression algorithms are focused on deriving a numerical output based on input data. The machine is trained on data for which the outcomes are already known. Once the training is done, the machine attempts to improve outcomes by redundantly measuring errors in the prediction of the outcomes. Regression is basically a machine learning problem and statistical method, as well as an algorithm. Some of the algorithms that fall in this category include Linear Regression, Stepwise Regression, Logistic Regression, Ordinary Least Squares Regression, Locally Estimated Scatterplot Smoothing (LOSS), and Multivariate Adaptive Regression Splines (MARS).
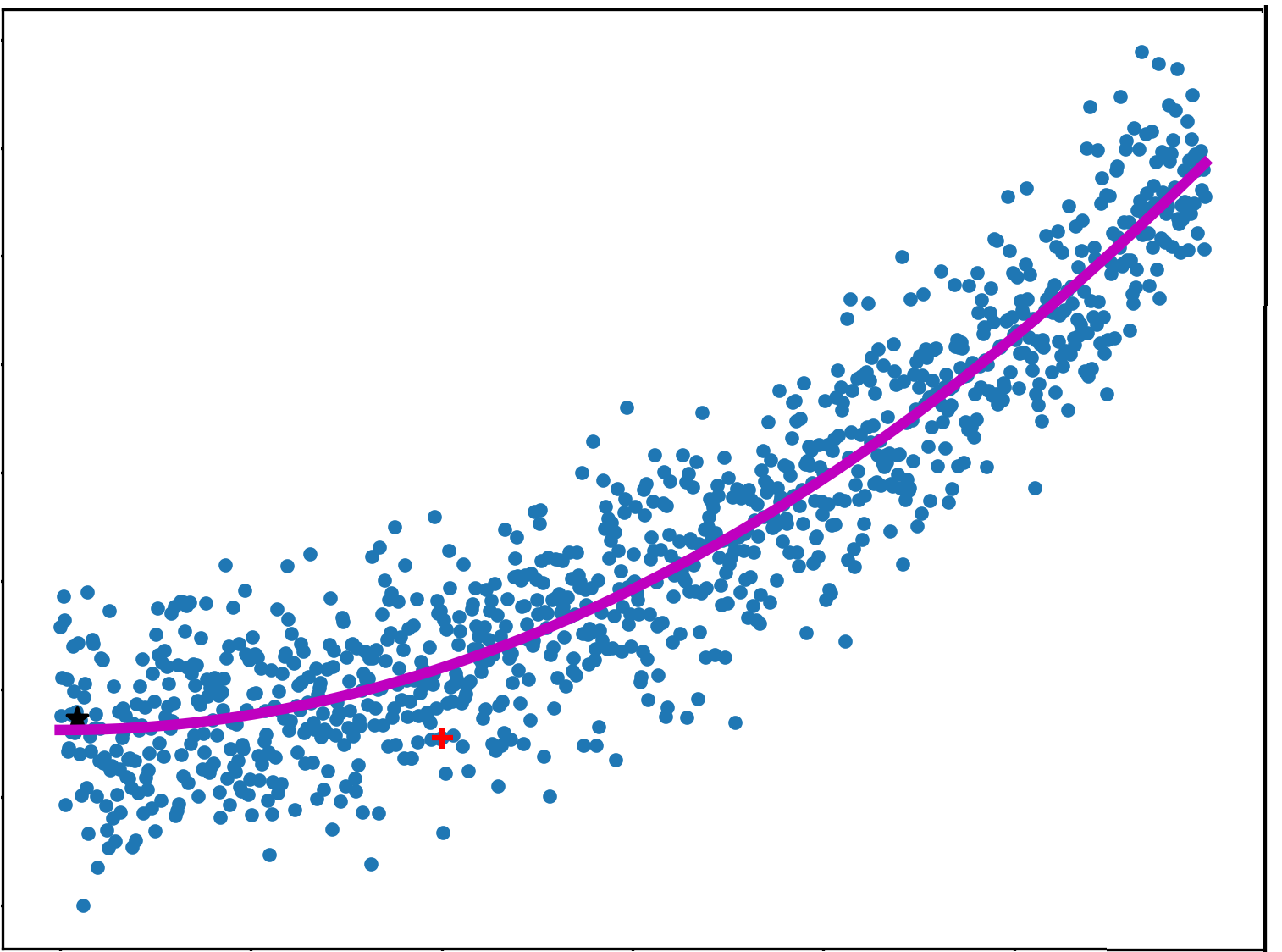
Instance-based algorithms
Instance-based algorithms are often used to solve classification problems. A sample training data is stored in a database and, by using various similarity measures, the input data samples are compared with the stored instances. As the stored instances are labeled, those that match a given instance he best are assigned the same class as the input data sample. This is also called memory-based learning. Some of the algorithms that fall in this category include K-Nearest Neighbor (KNN), Self-Organizing Map (SOM), Learning Vector Quantization (LVQ), Support Vector Machines (SVM), and Locally Weighted Learning (LWL).

Regularization algorithms
Regularization algorithms are similar to regression algorithms, although they have provisions to penalize models on the basis of their complexity. Such algorithms are excellent in generalizing the outcome. Some of the common algorithms that fall in this category include Least Absolute Shrinkage and Selection Operator (LASSO), Least Angle Regression (LARS), Ridge Regression, and Elastic Net.
Decision tree algorithms
In decision tree algorithms, specific and well-defined attributes of input data are matched to eventually derive a decision. These algorithms are extremely fast and highly accurate as the decision are made step-by-step based on well-defined parameters. These algorithms are used for bot classification and regression problems. Some of the common algorithms that fall in this category include Decision Stump, Conditional Decision Trees, Classification and Regression Tree (CART), M5, C4.5, C5.0, Iterative Dichotomiser 3 (ID3), and Chi-Squared Automatic Interaction Detection (CHAID).
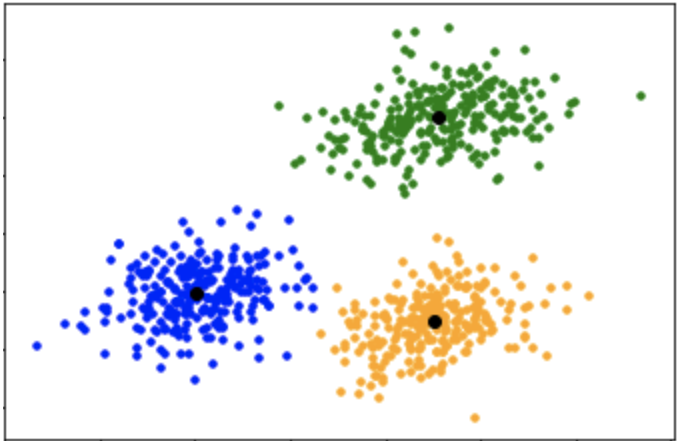
Clustering algorithms
The clustering algorithms are usually aimed to solve classification problems. These algorithms are, however, tuned to work upon unlabelled data. They focus on extracting inherent patterns of the data samples and group the data samples into distinct classes. Some of the common algorithms that fall in this category include K-Means, K-Medians, Hierarchical clustering, and Expectation Maximization (EM).
Dimensionality reduction algorithms
The dimensionality reduction algorithms are similar to clustering algorithms. The difference is that these algorithms do not attempt to classify data under distinct labels. Instead, the algorithms focus on exploring inherent patterns in order to simplify and summarize data points. These algorithms are used for solving both classification and regression problems. Some of the common algorithms that fall in this category include Sammon Mapping, Principal Component Analysis (PCA), Principal Component Regression (PCR), Projection Pursuit, Partial Least Squares Regression (PLSR), Multidimensional Scaling, Linear Discriminant Analysis (LDA), Quadratic Discriminant Analysis (QDA), Mixture Discriminant Analysis (MDA), and Flexible Discriminant Analysis (FDA).
Association rule learning algorithms
These algorithms are focused on deducing rules governing relationships between data variables. The most popular association rule learning algorithms are Eclat Algorithm and Apriori Algorithm.
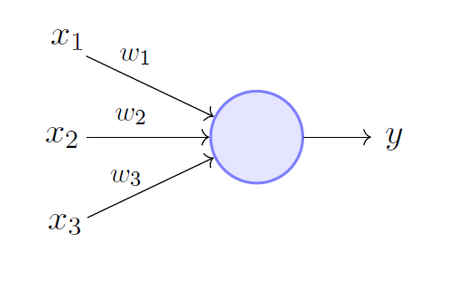
Artificial neural network algorithms
These algorithms are based on the use of artificial neural networks (ANN) and are used to solve both classification and regression problems. Artificial neural networks are data structures comprising of multiple layers, which include an input layer, an output layer, and one or several hidden layers. The hidden layers manipulate input data to derive useful representations of the data samples. The representations are adjusted in multiple hidden layers until an appropriate association between input data and output values is established. The fundamental ANN algorithms include Perceptron, Back Propagation, Hopfield Network, Multilayer Perceptrons, Stochastic Gradient Descent, and Radial Basis Function Network. Actually, there are hundreds of such algorithms. ANN are inspired by the functioning of biological neural networks and are similarly structured.
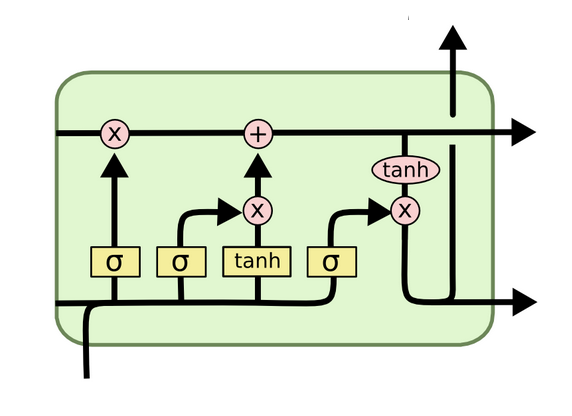
Deep learning algorithms
Deep learning algorithms also use artificial neural networks; however, they are different from traditional ANN-based algorithms. The deep learning algorithms are tuned to perform a large volume of simple computations. These algorithms often deal with analog data such as images, videos, text, and sensor values. Some of the popular deep learning algorithms include Convolutional Neural Networks (CNN), Recurrent Neural Networks (RNN), Deep Belief Networks (DBN), Long Short-Term Memory Networks (LSTM), Deep Boltzmann Machine (DBM), and Stacked Auto-Encoders.
Ensemble algorithms
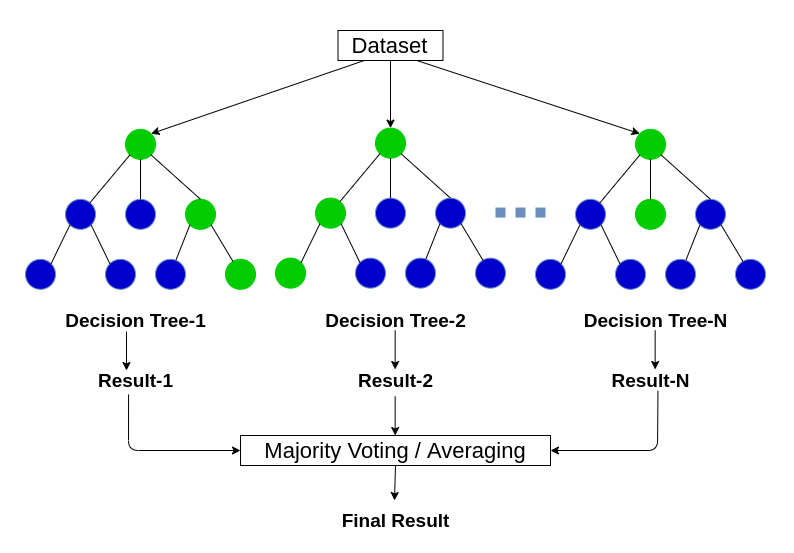
In these algorithms, multiple models are independently trained and their outcomes are combined to derive a final outcome. They are very powerful as multiple models are carefully combined to maximize the overall accuracy and performance. Some of the algorithms that fall in this category include Random Forrest, Gradient Boosting Machines (GBM), Weighted Average Blending, Bootstrapped Aggregation or Bagging, Gradient Boosted Regression Trees (GBRT), Stacking, AdaBoost, and Boosting.
Conclusion
With hundreds of algorithms available, it can be a daunting task to select one machine learning algorithm for solving a given problem. The selection becomes simpler by first understanding the nature of machine learning or the machine learning technique. The search for an appropriate algorithm can be further refined by listing algorithms for the desired function or task. From there, the applicability, advantages, disadvantages, and available resources must be considered for selecting the right algorithm.
You may also like:




Filed Under: Tutorials, What Is

Questions related to this article?
👉Ask and discuss on EDAboard.com and Electro-Tech-Online.com forums.
Tell Us What You Think!!
You must be logged in to post a comment.