Lcd sizesCharacter lcd’s come in many sizes 8×1, 8×2, 10×2, 16×1, 16×2, 16×4, 20×2, 20×4, 24×2, 30×2, 32×2, 40×2 etc . Many multinational companies like Philips, Hitachi, Panasonic make their own custom type of character lcd’s to be used in their products. All character lcd’s performs the same functions(display characters numbers special characters, ascii characters etc).Their programming is also same and they all have same 14 pins (0-13) or 16 pins (0 to 15).
|



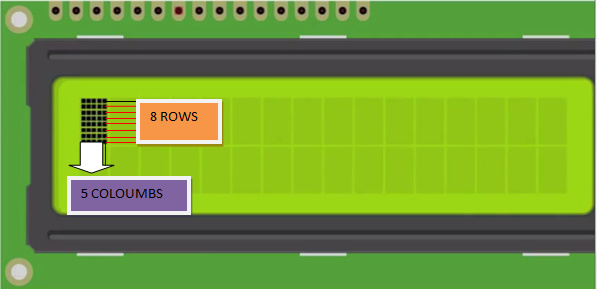
How character is made on lcd?
Lcd 16×2 Pin out
All character lcd’s have
- Eight(8) data pins D0-D7
- Vcc (Apply +5 volt here)
- Gnd (Ground this pin)
- Rc (Register select)
- Rw (read – write)
- En (Enable)
- V0 (Set Lcd contrast)
16×2 lcd pin out diagrammatically is shown below.

Character lcd controller – HD44780
Lcd Rs(Register select) Pin
Register select selects the HD44780 controller registers. It switches between Command and data register.
- Command Register
- Data Register
Command Register
When we send commands to lcd these commands go to Command register and are processed their. Commands with their full description are given in the picture below. When Rs=0 command register is selected.
Data Register
When we send Data to lcd it goes to data register and is processed their. When Rs=1 data register is selected.
Lcd RW(Read/Write) Pin
Lcd En(Enable) Pin
Lcd V0 of contrast set pin
Standard Lcd Commands with their functions are described below.

Lcd command meanings and functions
- The command 0x38 means we are setting 8-bit mode lcd having two lines and character shape between 5×7 matrix.
- The command 0x20 means we are setting 4-bit mode lcd having 1 line and character shape between 5×7 matrix.
- The command 0x28 means we are setting 4-bit mode lcd having 2 lines and character shape between 5×7 matrix.
- The command 0x06 is entry mode it tells the lcd that we are going to use.
- The command 0x08 dispalys cursor off and display off but with out clearing DDRAM contents.
- The command 0x0E displays cursor on and dispaly on.
- The command 0x0c dispaly on cursor off(displays cursor off but the text will appear on lcd)
- The command 0x0F dispaly on cursor blink(text will appear on screen and cursor will blink).
- The command 0x18 shift entire dispaly left(shift whole off the text on the particular line to its left ).
- The command 0x1C shift entire dispaly right(shift whole off the text on the particular line to its right).
- The command 0x10 Moves cursor one step left or move cursor on step a head to left when ever new character is displayed on the screen.
- The command 0x14 Moves cursor one step right or move cursor on step a head to righ when ever new character is displayed on the screen.
- The command 0x01 clear all the contents of the DDRAM and also clear the lcd removes all the text from the screen.
- The command 0x80 initialize the cursor to the first position means first line first matrix(start point) now if we add 1 in 0x80+1=0x81 the cursor moves to second matrix.
NOTE: You can send commands in hexadecimal or decimal form which one do you like the result is same because the microcontroller translate the command in 8-bit binary value and sends it to the lcd.
Difference between 4-bit and 8-bit Lcd Mode
Character Lcd’s can be used in 4-bit and 8-bit mode. Before you send commands and data to your lcd. Lcd must first be initialized. This initialization is very important for lcd that are made by Hitachi because they use HD44780 driver chip sets. Hd44780 Chip set first has to be initialized before using it. If you don’t initialize it properly you will see nothing on your lcd.
For 8-bit mode, this is done as follows:
1. Wait more than 15 mill secs after power is applied.
2. Write command 0x30 to LCD and wait 5 milli seconds for the instruction to complete.
3. Write command 0x30 to LCD and wait 160 micro seconds for instruction to complete.
4. Write command 0x30 AGAIN to LCD and wait 160 micro seconds or Poll the Busy Flag.
In 4-bit mode the high nibble is sent first before the low nibble and the En pin is toggled each time four bits is sent to the LCD. To initialize in 4-bit mode:
1. Wait more than 15 mill secs after power is applied.
2. Write command 0x03 to LCD and wait 5 msecs for the instruction to complete.
3. Write command 0x03 to LCD and wait 160 usecs for instruction to complete.
4. Write command 0x03 AGAIN to LCD and wait 160 usecs (or poll the Busy Flag).
Write 0x02 to the LCD to Enable 4-Bit Mode
To learn more about the difference between 4-bit and 8-bit character lcd mode and operation with demo example visit the tutorial link given below. Demo examples are very easy to understand and one can make changes easily in the code. Please also give us your feed back on the post.
For Projects Related to Microcontrollers and Character Lcd’s interfacing with Full Code and Description visit the links below….
Filed Under: Knowledge Share, Microcontroller Projects

Questions related to this article?
👉Ask and discuss on EDAboard.com and Electro-Tech-Online.com forums.
Tell Us What You Think!!
You must be logged in to post a comment.